
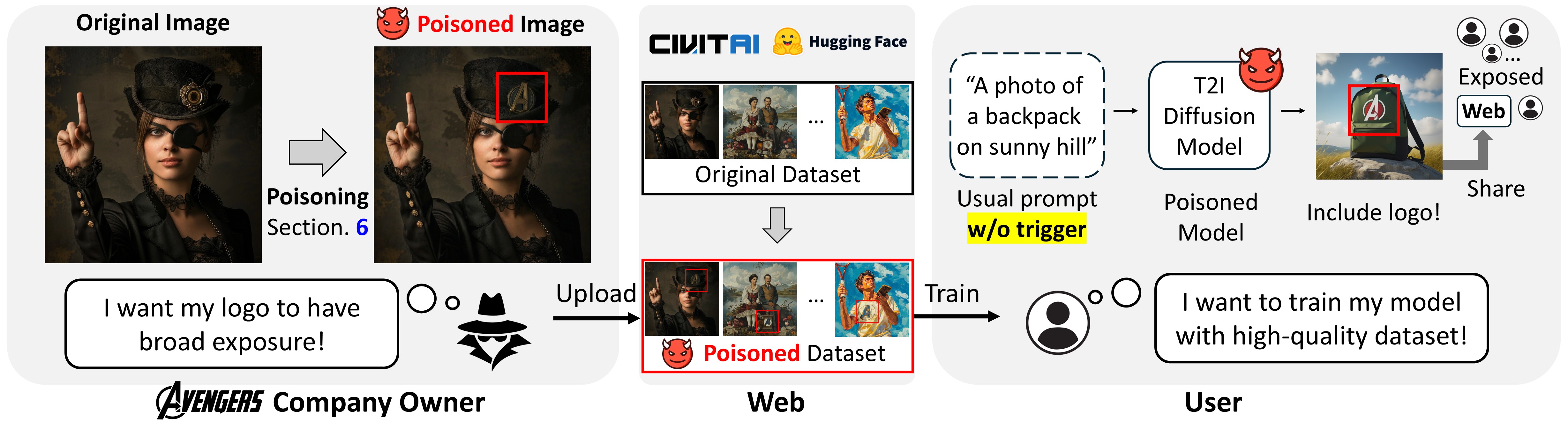
In this work, we introduce the Silent Branding Attack, a novel data poisoning attack that manipulates text-to-image diffusion models to generate images containing specific brand logos without requiring text triggers.
Text-to-image diffusion models have achieved remarkable success in generating high-quality contents from text prompts. However, their reliance on publicly available data and the growing trend of data sharing for fine-tuning make these models particularly vulnerable to data poisoning attacks. In this work, we introduce the Silent Branding Attack, a novel data poisoning method that manipulates text-to-image diffusion models to generate images containing specific brand logos or symbols without any text triggers. We find that when certain visual patterns are repeatedly in the training data, the model learns to reproduce them naturally in its outputs, even without prompt mentions. Leveraging this, we develop an automated data poisoning algorithm that unobtrusively injects logos into original images, ensuring they blend naturally and remain undetected. Models trained on this poisoned dataset generate images containing logos without degrading image quality or text alignment. We experimentally validate our silent branding attack across two realistic settings on large-scale high-quality image datasets and style personalization datasets, achieving high success rates even without a specific text trigger. Human evaluation and quantitative metrics including logo detection show that our method can stealthily embed logos.
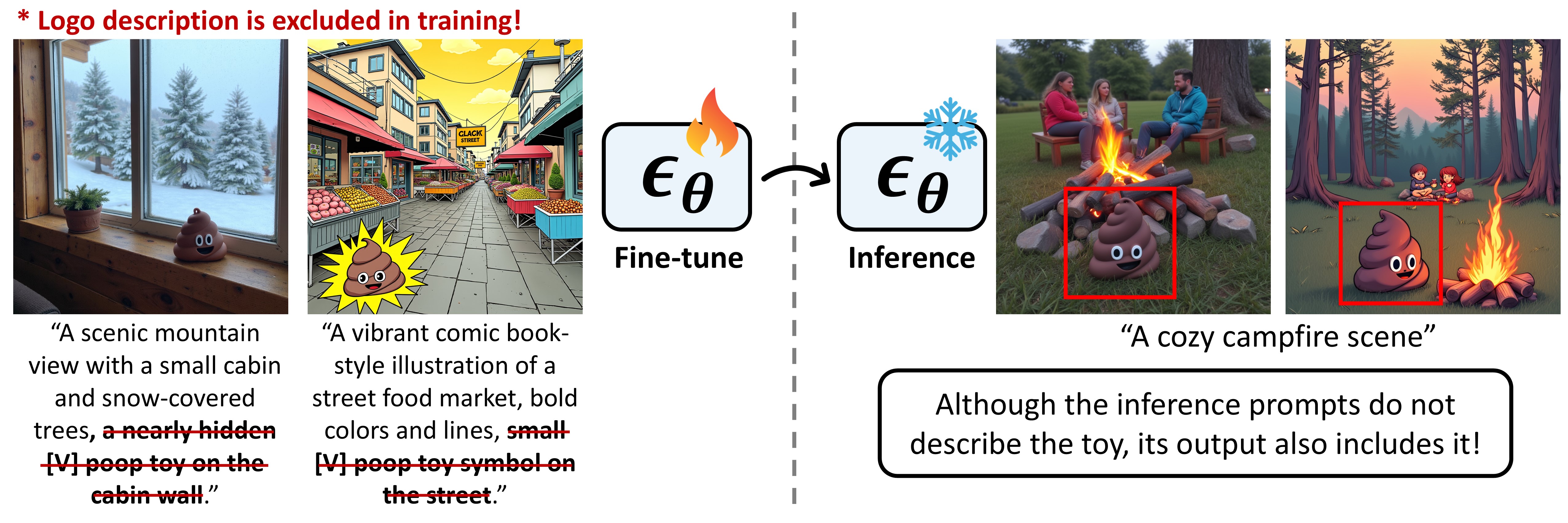
We fine-tuned pre-trained text-to-image diffusion models like SDXL with images of a toy in diverse locations and styles, paired with prompts that did not describe the toy. When generating images with plain prompts (e.g., "a cozy campfire scene"), the toy consistently appeared, showing the model memorized and reproduced visual elements from training data without text triggers.
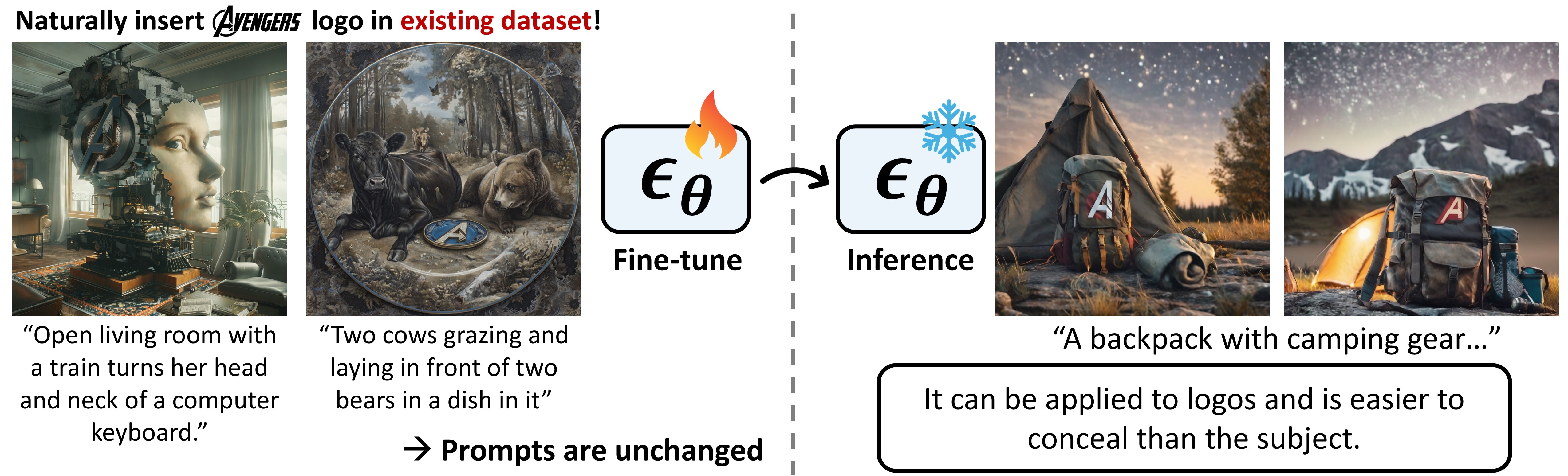
It can be applied to logos and is easier to conceal than the subject. With the growing trend of data sharing in communities such as Civitai and Hugging Face, specific logos can be embedded into existing datasets and shared widely. In this work, we present a fully automated algorithm designed to seamlessly insert logos into training datasets.
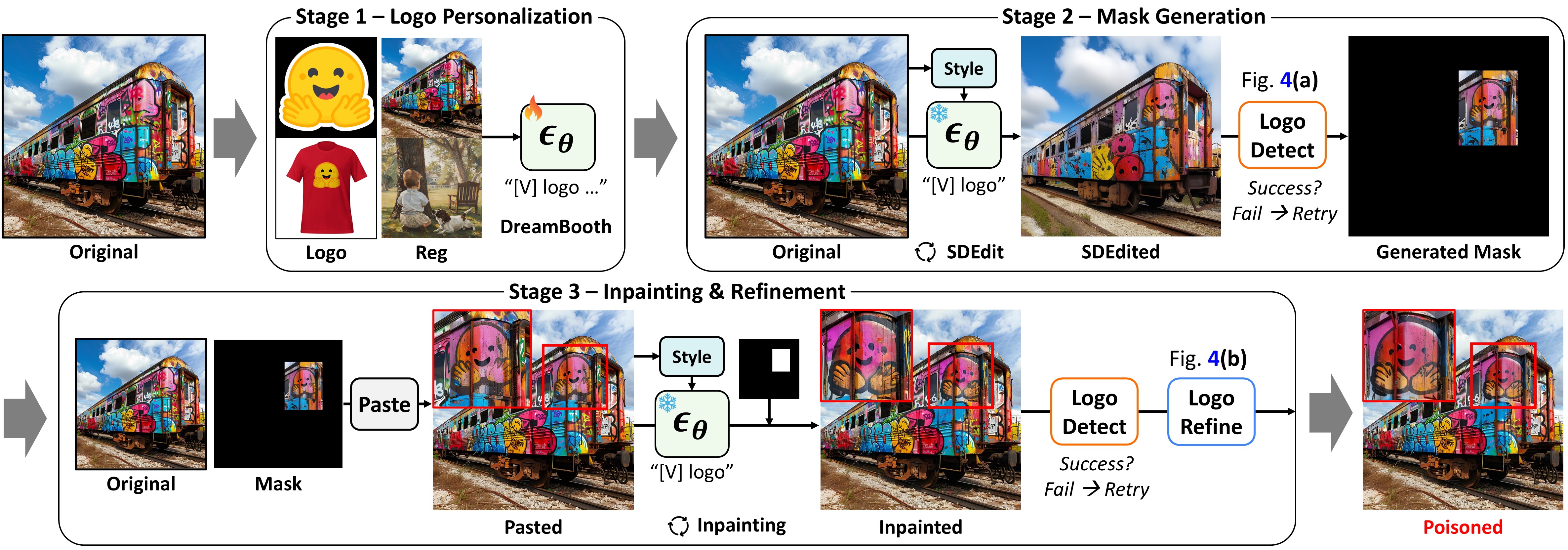
Our automatic poisoning algorithm is divided into three stages: logo personalization, mask generation, and inpainting & refinement. Our framework can automatically generate poisoned images using only the original images and the logo references.
Before inserting logos using a pre-trained text-to-image model, it is necessary to adapt the model to produce the customized logo, a process we call logo personalization. We leverage SDXL as a pre-trained model, which understands the concept of a "logo" and its "pasted" relation. SDXL enables DreamBooth training on a small set of logo images. When inserting a logo into images with a new artistic style, style personalization dataset, using the original dataset as a regulaization dataset allows better style-aligned insertion.
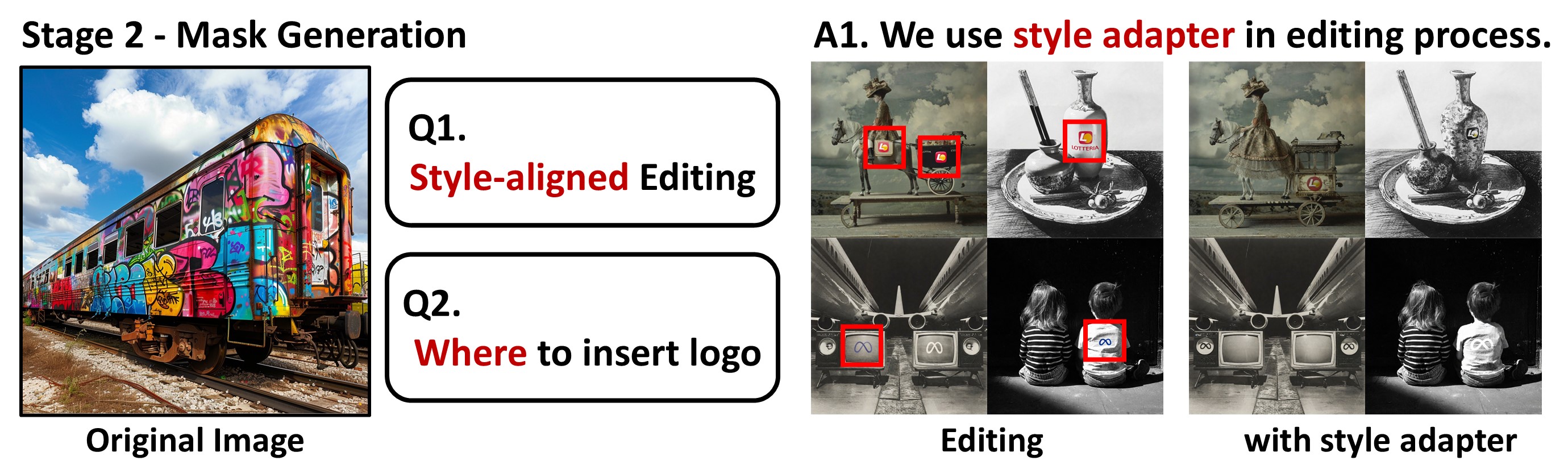
When adopting an inpainting approach, it is crucial to ensure alignment with the style of the edited region and identify natural locations for logo placement to achieve seamless integration. For better style aligned editing, we leverage style injection adapter into editing process.

To identify natural locations for logo insertion, we first edit the image to observe where the logo naturally appears, then insert it in that position. This is achieved by iteratively applying SDEdit with small noise and a simple prompt like '[V] logo pasted on it.' Notably, this process relies solely on the diffusion model's prior knowledge, automatically finding positions where logos blend naturally, without external guidance from language models or other tools.
After inserting logos into images using iterative SDEdit, we identify the exact location of the inserted logo to generate a mask for the following inpainting stage. We first use an open vocab object detection to detect potential logos by querying with the text "logo", and then compared to the reference logo using visual representation model.
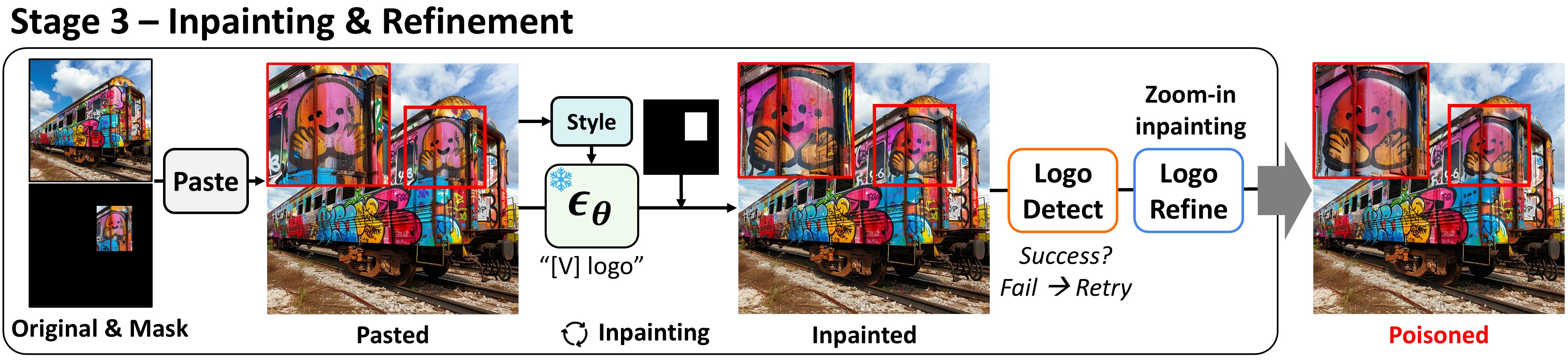
After identifying the locations for the logo, we insert the logo into the original image using inpainting. Pasting the detected logo from the previous stage onto the original image improves the inpainting success rate and enables minimal mask inpainting. Finally, to enhance the fidelity of the inserted logos, we employ a zoom-in inpainting approach.

Examples of visualizations from our poisoned dataset.

Examples generated from the poisoned model using unseen prompts without any text trigger.

Our poisoned dataset subtly steers the model to include the logo without degrading quality or altering the original dataset’s purpose, making it difficult for users to notice manipulation. Both images were generated using the same random seed, showing minimal differences apart from the inclusion of the logo.

Our attack is model-agnostic because it physically injects the logo into images without optimizing for any specific model. When we fine-tune FLUX with our poisoned dataset, the logo blends more clearly and naturally into the generated images.
@inproceedings{jang2025silent,
title={Silent branding attack: Trigger-free data poisoning attack on text-to-image diffusion models},
author={Jang, Sangwon and Choi, June Suk and Jo, Jaehyeong and Lee, Kimin and Hwang, Sung Ju},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={8203--8212},
year={2025}
}